F2HF: Feed-Forward Network as a Noisy Head Filter in Vision Transformer Explanations
ICCIT 2025
Khulna University of Engineering & Technology
Abstract
Overview
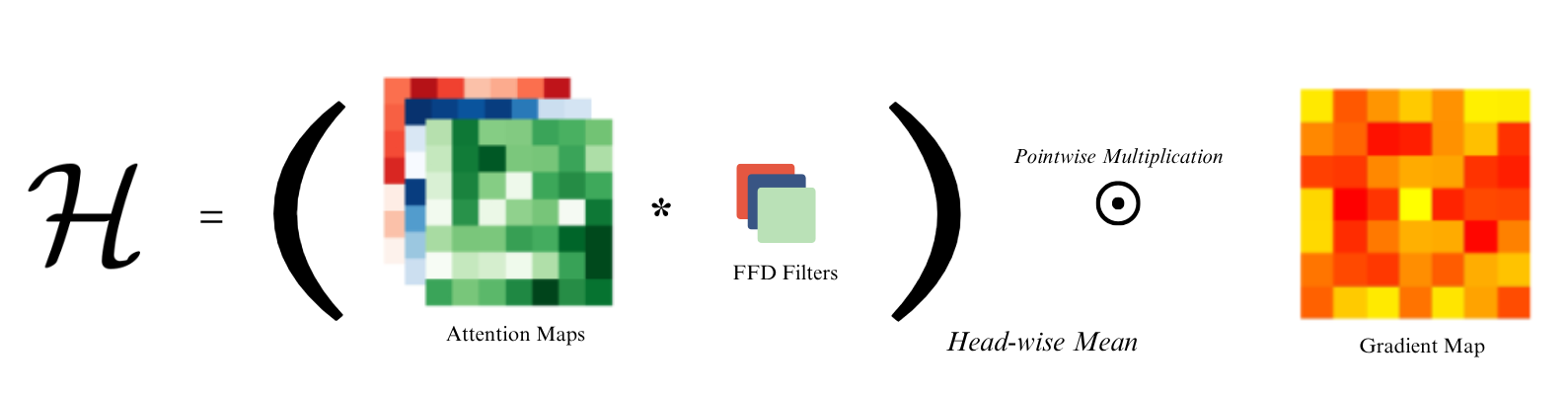
Vision Transformers (ViTs) have become a key component of modern computer vision tasks, yet creating faithful and holistic explanations for their decisions remains an ongoing challenge. Many existing interpretability methods are either model-agnostic or, when specifically designed for transformers, primarily focus on the attention mechanism. However, attention maps are inherently not class-specific and often introduce noise, checkerboard artifacts, and irrelevant background attributions.
Key idea
Recent work has shown that the Feed-Forward Network (FFD) in each transformer block acts as a factual memory and a token filter. Existing methods often fail to fully account for the FFD's role, representing a significant gap in faithfully interpreting Transformer models. To address this, we introduce F2HF (Feed-Forward Head Filtering Saliency Generator).
In our approach, the generation of the attention map leverages the previous block's final linear layer to filter out unnecessary attention heads. By clipping negative values and focusing only on positive weights, we ensure that the most important class-specific features are retained while noisy, background-focused heads are suppressed.
Results
Objective and Subjective Evaluation
The addition of Feed-Forward filtering in the encoder attention map provides significant improvements over the baseline (which accumulates block attention maps and multiplies them with the classifier gradient heatmap):
- Intersection over Union (IoU): Up to 16.4% improvement compared to existing methods.
- Precision and F1 Score: Consistent and notable improvements were observed across these metrics during objective segmentation and perturbation tests.
Furthermore, in a subjective test where three human subjects blindly selected the less noisy heatmap across 500 images, the saliency map generated by F2HF was chosen in 84% of the cases. When target objects have minimal presence, F2HF almost always outperforms existing methods by generating a faithful, class-specific, and less noisy heatmap.
Qualitative Comparison
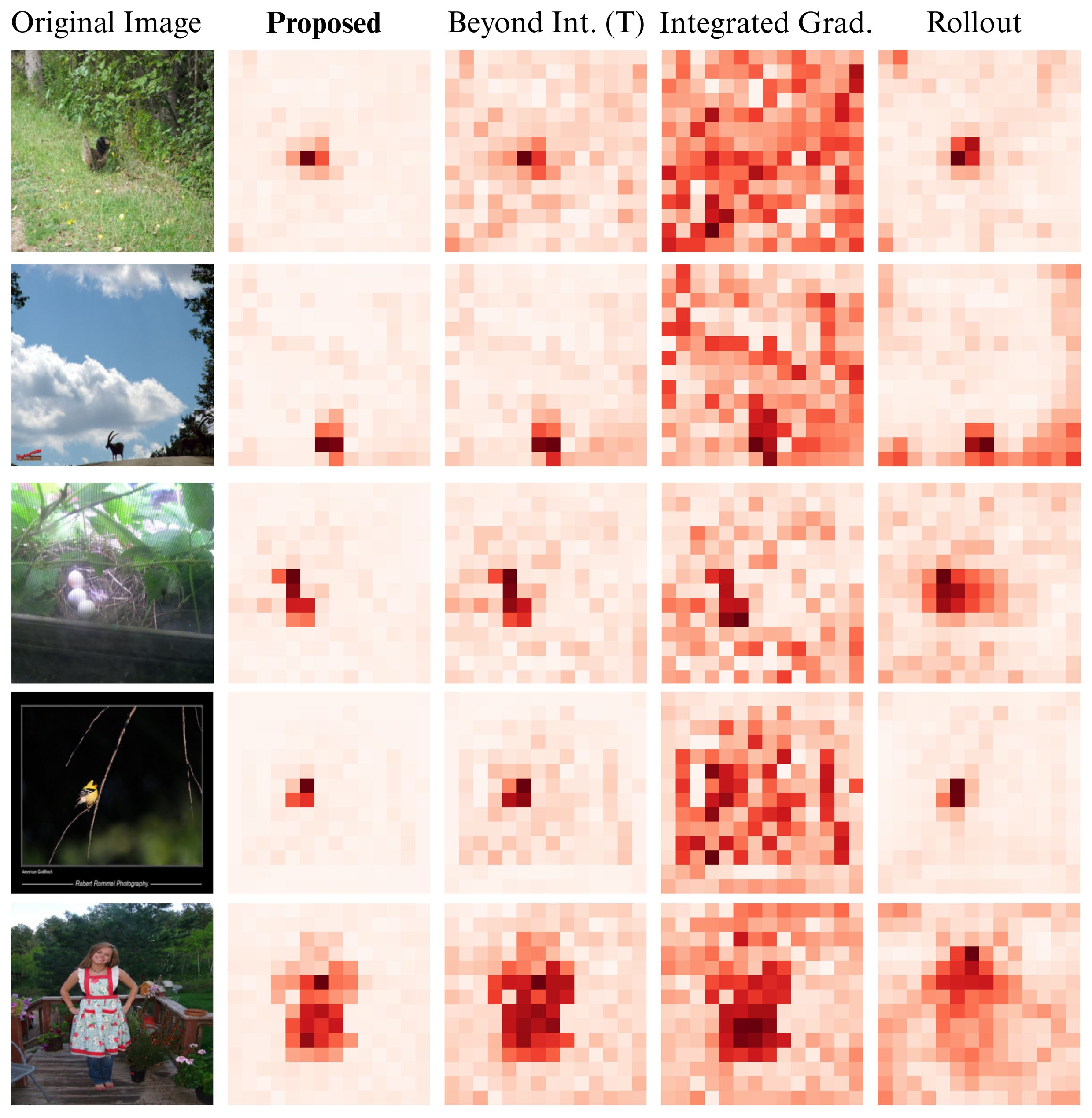
Segmentation Test Comparison
| Architecture | Method | Pix. Acc (%) | mIoU | mAP | mF1 | mIoU (FG) |
|---|---|---|---|---|---|---|
| ViT Base | Proposed (F2HF) | 81.36 | 0.65 | 0.88 | 0.45 | 0.53 |
| Beyond Int.-T | 77.47 | 0.60 | 0.87 | 0.44 | 0.49 | |
| Beyond Int.-H | 78.04 | 0.61 | 0.86 | 0.44 | 0.49 | |
| Rollout | 70.33 | 0.52 | 0.82 | 0.42 | 0.41 | |
| Raw Attention | 65.91 | 0.41 | 0.72 | 0.19 | 0.20 | |
| Int. Gradient | 67.31 | 0.49 | 0.78 | 0.38 | 0.38 | |
| GradCAM | 65.91 | 0.41 | 0.72 | 0.19 | 0.20 | |
| ViT Large | Proposed (F2HF) | 77.35 | 0.61 | 0.85 | 0.42 | 0.50 |
| Beyond Int.-T | 71.46 | 0.52 | 0.82 | 0.39 | 0.40 | |
| Beyond Int.-H | 77.14 | 0.59 | 0.85 | 0.43 | 0.47 | |
| Rollout | 66.00 | 0.47 | 0.79 | 0.39 | 0.36 | |
| Raw Attention | 67.41 | 0.40 | 0.70 | 0.11 | 0.11 | |
| Int. Gradient | 65.89 | 0.43 | 0.72 | 0.30 | 0.20 | |
| GradCAM | 63.49 | 0.40 | 0.70 | 0.10 | 0.10 |
Positive Perturbation Test Results (Lower is better)
| Perturbation | Top-K | Proposed (F2HF) | B. Int. (T) | B. Int. (H) | Rollout | IG |
|---|---|---|---|---|---|---|
| 10% | Top-1 | 62.14% | 65.37% | 63.60% | 63.55% | 72.10% |
| Top-3 | 77.26% | 80.33% | 78.88% | 78.60% | 85.68% | |
| Top-5 | 81.94% | 84.56% | 83.43% | 82.95% | 89.10% | |
| 20% | Top-1 | 48.37% | 53.51% | 63.59% | 50.76% | 65.94% |
| Top-3 | 63.80% | 69.03% | 78.87% | 66.27% | 80.39% | |
| Top-5 | 69.82% | 74.58% | 83.43% | 71.84% | 84.49% | |
| 30% | Top-1 | 37.50% | 43.59% | 41.08% | 40.96% | 59.25% |
| Top-3 | 52.58% | 58.74% | 56.15% | 55.82% | 74.31% | |
| Top-5 | 59.10% | 64.70% | 62.23% | 61.76% | 79.26% |
Note: Please reach out to me via LinkedIn or email if you need the paper PDF.
Citation
@INPROCEEDINGS{11491078,
author={Hossen, Imran and Alam, Kazi Saeed},
booktitle={2025 28th International Conference on Computer and Information Technology (ICCIT)},
title={F2HF: Feed-Forward Network as a Noisy Head Filter in Vision Transformer Explanations},
year={2025},
volume={},
number={},
pages={2675-2680},
keywords={Satellite images;Earth Observing System;Feeds;Antennas;Radio broadcasting;Frequency modulation;Filtering;Filters;Circuits and systems;HTTP;interpretability;attention;feed-forward network},
doi={10.1109/ICCIT68739.2025.11491078}}