Virtual Try-On Model with Mutual Self-Attention
Dual U-Net Diffusion Model
Description
This project presents a virtual dress try-on application powered by a custom dual-U-Net diffusion architecture. The model is trained to transfer a clothing garment (cloth_image) onto a person's photo (person_image) while preserving the high-fidelity texture, pattern, and color of the fabric. Rather than utilizing a single U-Net with cross-attention, our approach uses a dedicated 'Cloth U-Net' to extract multi-scale garment representations, and couples it with a 'Denoising U-Net' via a custom mutual self-attention layer. This mechanism allows the generator to retrieve and apply localized details of the clothing item onto the generated human frame, achieving a highly realistic try-on effect with an outstanding FID score of 9.01.
Overview
This project introduces a dual-U-Net diffusion framework for virtual try-on, allowing users to select a clothing garment and see it realistically mapped onto any target person's image.
Try it out live at vilt.vercel.app or watch the demonstration video on YouTube.
Model Architecture
The core of our approach is a two-stage, dual-U-Net diffusion model that bypasses standard text-prompt conditioning in favor of direct visual feature injecting:
- Cloth U-Net: Processes the VAE-encoded garment image to capture textures, patterns, and colors at multiple scales.
- Denoising U-Net: Synthesizes the final output by progressively denoising a random latent guided by the target person's body shape and the extracted garment features.
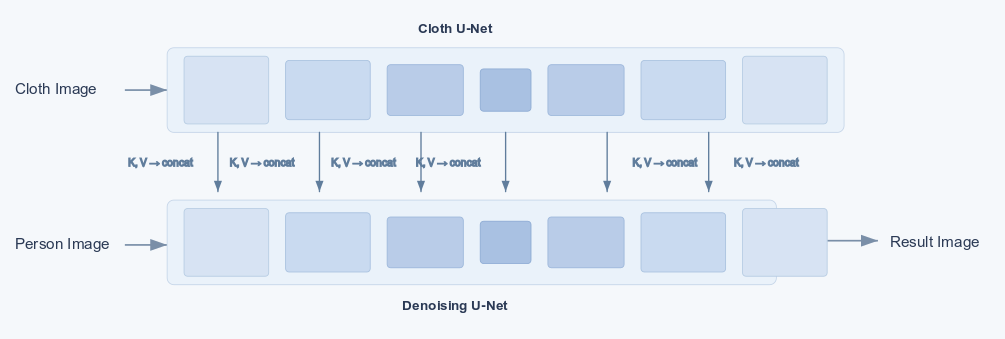
Key Mechanism: Mutual Self-Attention
To preserve intricate fabric patterns, the self-attention blocks of the two U-Nets are bridged:
- Cloth Feature Collection: During the forward pass of the Cloth U-Net, the controller captures the multi-scale representations at each attention block.
- Garment Injection: In the Denoising U-Net, the attention layers query the person features, but concatenate their Keys ($K$) and Values ($V$) with the captured garment features. The attention is computed as: $$\text{Attention}(Q_{\text{person}}, K_{[\text{person}+\text{garment}]}, V_{[\text{person}+\text{garment}]})$$ This forces the network to look up and pull textures directly from the garment representation, cleanly "draping" the fabric onto the person.
Results & Comparison
The model achieves near state-of-the-art results, generating extremely clean details without warping or washing out patterns:
| Model | FID Score (Lower is better) |
|---|---|
| Baseline Try-On Model | 14.25 |
| Our Dual U-Net Model (ViLT) | 9.01 |

