F2HF: Feed-Forward Network as a Noisy Head Filter in Vision Transformer Explanations
ICCIT 2025
Khulna University of Engineering & Technology
Abstract
The Black Box Problem of Vision Transformers
Vision Transformers (ViTs) have taken the computer vision world by storm, beating out traditional convolutional networks across a multitude of tasks. But they are incredibly difficult to interpret.
When a ViT decides that an image contains a dog, how do we know what part of the image it's actually looking at? For critical applications like medical diagnosis or autonomous driving, we can't afford to blindly trust a "black box" model. We need faithfully generated visual explanations (saliency maps) that highlight the exact pixels driving the model's decisions.
Unfortunately, current interpretability methods struggle with this. If you ask a standard interpretability tool to highlight what a ViT sees, you often get a noisy, checkerboard-like heatmap. It highlights the background, irrelevant objects, and random noise, completely missing the fact that we only care about the class specific to our prompt.
Why Do Existing Methods Fail?
Most existing methods either treat the model as a complete black box, or they peek inside and focus exclusively on the Attention Mechanism. But attention maps are inherently not class-specific!
This is where a critical gap lies: The Feed-Forward Network (FFD). Every transformer block contains an FFD, yet most interpretability methods ignore it. Recent research reveals that the FFD doesn't just process data—it acts as a factual memory bank and a token filter, suppressing irrelevant information.
Enter F2HF: Feed-Forward Head Filtering
To solve the noise problem, we decided to leverage the FFD rather than ignore it. We introduce F2HF, an interpretability method that uses the Feed-Forward network as an active attention filter.
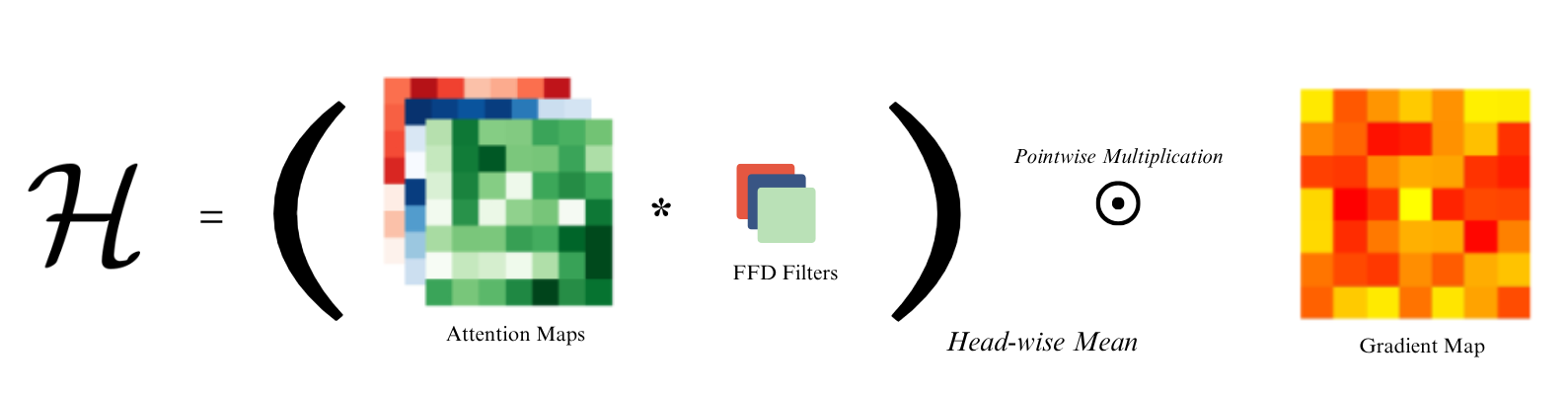
How it works: Instead of blindly accumulating attention maps, F2HF uses the weights of the FFD to filter out unnecessary attention heads. By clipping negative values and keeping only the positive weights, we ensure that noisy, background-focused heads are completely suppressed. The result? A pristine, class-specific heatmap.
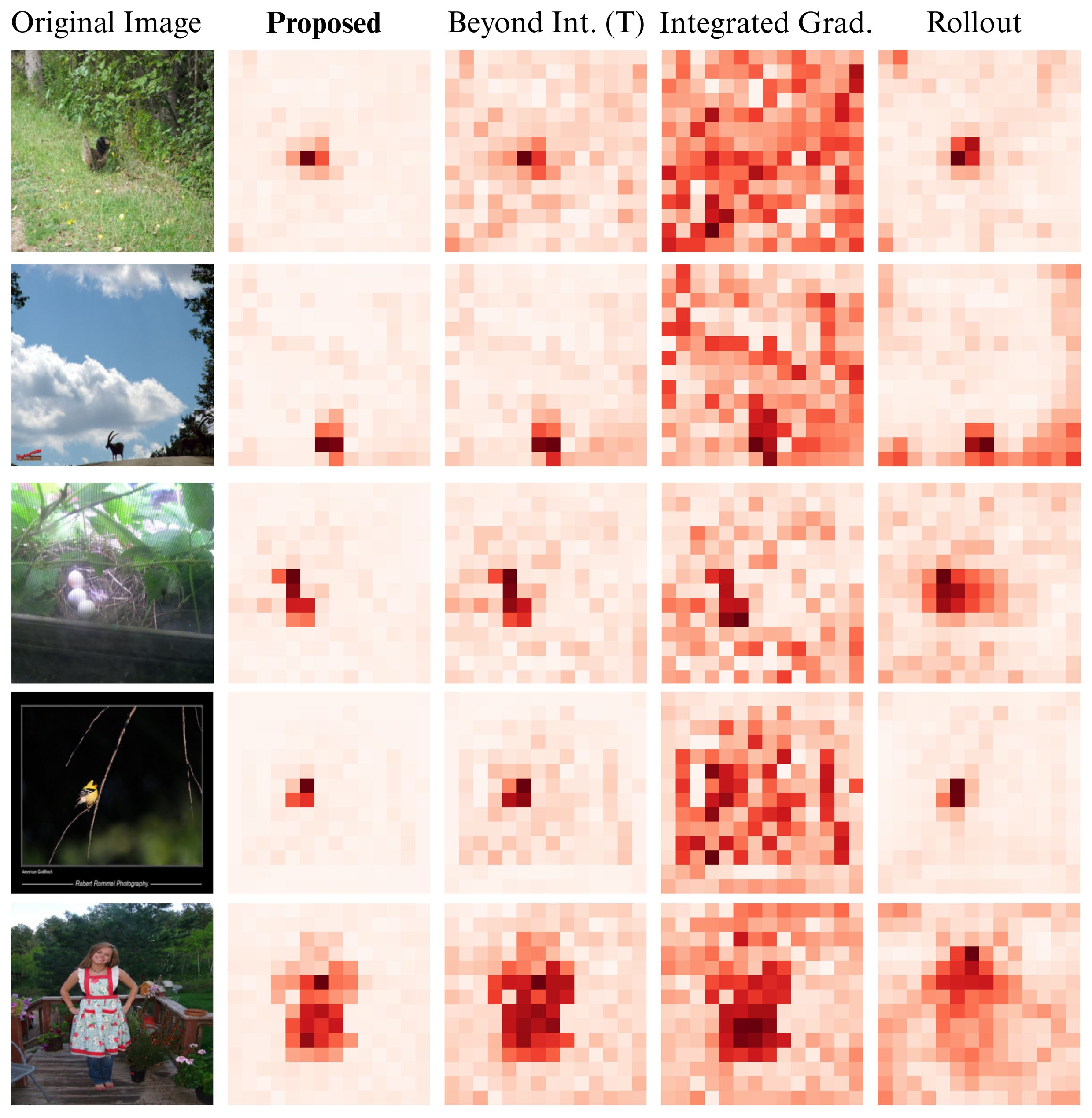
Results: Does it actually work?
We rigorously tested F2HF against state-of-the-art baselines. The results were incredibly promising.
What humans think
We ran a subjective blind test where three human subjects reviewed 500 images and chose the least noisy, most accurate heatmap. In 84% of the cases, humans preferred F2HF over existing methods.
What the numbers say
Quantitatively, the addition of Feed-Forward filtering provides massive improvements. We saw up to a 16.4% improvement in Intersection over Union (IoU), along with consistent leaps in Precision and F1 scores.
Segmentation Test Comparison
| Architecture | Method | Pix. Acc (%) | mIoU | mAP | mF1 | mIoU (FG) |
|---|---|---|---|---|---|---|
| ViT Base | Proposed (F2HF) | 81.36 | 0.65 | 0.88 | 0.45 | 0.53 |
| Beyond Int.-T | 77.47 | 0.60 | 0.87 | 0.44 | 0.49 | |
| Beyond Int.-H | 78.04 | 0.61 | 0.86 | 0.44 | 0.49 | |
| Rollout | 70.33 | 0.52 | 0.82 | 0.42 | 0.41 | |
| Raw Attention | 65.91 | 0.41 | 0.72 | 0.19 | 0.20 | |
| Int. Gradient | 67.31 | 0.49 | 0.78 | 0.38 | 0.38 | |
| GradCAM | 65.91 | 0.41 | 0.72 | 0.19 | 0.20 | |
| ViT Large | Proposed (F2HF) | 77.35 | 0.61 | 0.85 | 0.42 | 0.50 |
| Beyond Int.-T | 71.46 | 0.52 | 0.82 | 0.39 | 0.40 | |
| Beyond Int.-H | 77.14 | 0.59 | 0.85 | 0.43 | 0.47 | |
| Rollout | 66.00 | 0.47 | 0.79 | 0.39 | 0.36 | |
| Raw Attention | 67.41 | 0.40 | 0.70 | 0.11 | 0.11 | |
| Int. Gradient | 65.89 | 0.43 | 0.72 | 0.30 | 0.20 | |
| GradCAM | 63.49 | 0.40 | 0.70 | 0.10 | 0.10 |
Positive Perturbation Test Results (Lower is better)
| Perturbation | Top-K | Proposed (F2HF) | B. Int. (T) | B. Int. (H) | Rollout | IG |
|---|---|---|---|---|---|---|
| 10% | Top-1 | 62.14% | 65.37% | 63.60% | 63.55% | 72.10% |
| Top-3 | 77.26% | 80.33% | 78.88% | 78.60% | 85.68% | |
| Top-5 | 81.94% | 84.56% | 83.43% | 82.95% | 89.10% | |
| 20% | Top-1 | 48.37% | 53.51% | 63.59% | 50.76% | 65.94% |
| Top-3 | 63.80% | 69.03% | 78.87% | 66.27% | 80.39% | |
| Top-5 | 69.82% | 74.58% | 83.43% | 71.84% | 84.49% | |
| 30% | Top-1 | 37.50% | 43.59% | 41.08% | 40.96% | 59.25% |
| Top-3 | 52.58% | 58.74% | 56.15% | 55.82% | 74.31% | |
| Top-5 | 59.10% | 64.70% | 62.23% | 61.76% | 79.26% |
Note: Please reach out to me via LinkedIn or email if you need the paper PDF.
Citation
@INPROCEEDINGS{11491078,
author={Hossen, Imran and Alam, Kazi Saeed},
booktitle={2025 28th International Conference on Computer and Information Technology (ICCIT)},
title={F2HF: Feed-Forward Network as a Noisy Head Filter in Vision Transformer Explanations},
year={2025},
volume={},
number={},
pages={2675-2680},
keywords={Satellite images;Earth Observing System;Feeds;Antennas;Radio broadcasting;Frequency modulation;Filtering;Filters;Circuits and systems;HTTP;interpretability;attention;feed-forward network},
doi={10.1109/ICCIT68739.2025.11491078}}